才気に富んだことは個人が行うのが通例であり、信じがたきバカ さ加減は大抵組織に帰されるものである。 -- Jon Bentley
役に立たないソフトウェアを作るのが好きだ。面倒な作業を楽にす る横着ソフトウェアもいいが、たまには人を呆れさせるくだらない ソフトウェアを作るのも楽しい。
以前に私が開発した cdbiff*2というソフト ウェアは、メールが届くと PC の CD-ROMドライブが開いてメール の到着を通知するという役に立たないものであったが、そのくだら なさが受けて予想外の好評を得た。今回は、そうした役に立たない ソフトウェアの 1つである、小うるさい端末 chatty*3 を紹介する。

cdbiff
chattyとは
chatty はユーザが入力した文字列に応じて端末のタイトルバーに 小うるさいメッセージを表示するソフトウェアである。「だから何 なんだ」と言われるかもしれないが、本当にそれだけのソフトウェ アなのだから仕方がない。
chatty

chatty
chatty

chatty
chatty と似たソフトウェアとして A Helpful TTY (ah-tty) *4 がある。ah-tty は端末 の下 3行をメッセージを表示する領域として割り当て、コマンドラ インへのユーザの入力に応じてへルプメッセージを表示する。
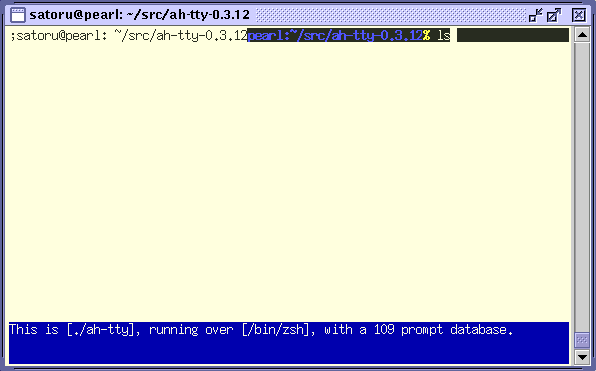
ah-tty は chatty と異なり実用性を重視したソフトウェアだが、 ah-tty が内部的に行っている端末エミュレーションに限界がある ため、制御コードを正しく処理できずに端末の表示が乱れるという 問題がある。
ah-tty
表示が乱れたah-tty
一方、 chatty は内部的に端末エミュレーションなどの複雑な処理 は行っていたいため、このような問題は起きない。
chattyの仕組み
chatty は、ユーザの入力を監視して、辞書に登録された文字列が 現われたときに端末のタイトルバーにメッセージを出力する。この 仕組みは、2002年4月号で紹介した ttyrec *5 と同様に、scriptコ マンドを改造して実現した。script は端末に出力されたすべての 文字列をファイルに保存するコマンドである*6。
scriptコマンドのソースを読むと、入力を処理する doinput 関数 が見つかる。
void
doinput()
{
register int cc;
char ibuf[BUFSIZ];
(void) fclose(fscript);
#ifdef HAVE_openpty
(void) close(slave);
#endif
while ((cc = read(0, ibuf, BUFSIZ)) > 0)
(void) write(master, ibuf, cc);
done();
}
そこで、この関数の while ループに、ユーザの入力を監視する関 数 watch_input を追加して、chatty の仕組みを実現した。
while ((cc = read(0, ibuf, BUFSIZ)) > 0) {
watch_input(dict, revbuf, ibuf, cc);
(void) write(master, ibuf, cc);
}
scriptコマンドでは端末に出力された文字列をファイルに保存す る処理が行われているが、chatty では保存の処理は不要であるた め、保存に関するコードをすべて除去している。
辞書のデータ構造
メッセージは次のような辞書に定義される。メッセージを追加する には chatty-dict.ja というテキストファイルを編集すればいい。
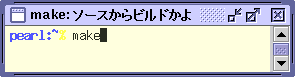
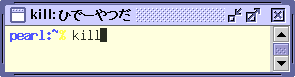
make ソースからビルドかよ mail 仕事しないでメールばっかり man google使えよ xman うげ。こんなのあったのか
このような辞書をプログラムで表現するデータ構造として、最初に 考えたのがリストである。しかし、リストは辞書に登録される項目 が増えるに従って検索が遅くなるという欠点を持つ。実際には上の ような小さな辞書では検索の速度は問題にならないが、リストで実 装してもプログラミングとしておもしろくないという理由もあって、 採用を見送った。
次の候補としてハッシュを考えた。ハッシュは高速な辞書検索に適 したデータ構造である。しかし、ハッシュではキーに完全に一致す る項目しか検索することができないため、m というキーで検索して make, mail, man を見つけるような前方一致の検索は行えない。そ こで、前方一致の検索が行えるデータ構造として、木を採用するこ とに決めた。
高速な辞書検索を実現する木として、トライ (TRIE) と呼ばれるも のがある。上の辞書をトライで表現した図を次に示す。メッセージ を持つ節は二重丸で示した。
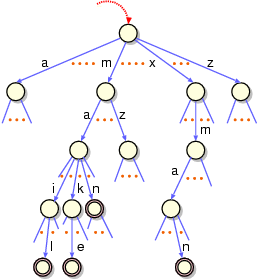
TRIE
トライの探索は矢印で示した最上部の節 (根) から開始する。各節 はキーの文字の種類と同じ数の枝を持ち、探索はキーの文字に対応 した枝を選択するだけで進めることができる。この例では、各節は a から z までの 26本の枝を持っている。たとえば、キーが man ならば、最初に m の枝を選択し、次に a の枝、最後に n の枝を 選んで進めていけば探索が完了する。
トライの特徴は、辞書に登録されている項目の数がどんなに多くて も、キーの長さに比例した時間で探索が行えるという点である。し かし、トライは高速な探索を実現する一方で、メモリを大量に消費 するという欠点を持つ。図の例では、最大4文字の項目に対応する 5段のトライを示したが、それだけでも 1 + 26 + 26^2 + 26^3 + 26^4 = 475,255 個もの節を持つ。このため、キーの文字種やキー の長さがが増えると、すぐにメモリに収まらなくなってしまう。
そこで、chatty では辞書のデータ構造として、トライを簡略化し た二分木を採用した。さきほどの辞書を簡略化したトライで表現し た図を次に示す。メッセージを持つ節は二重の四角で示した。
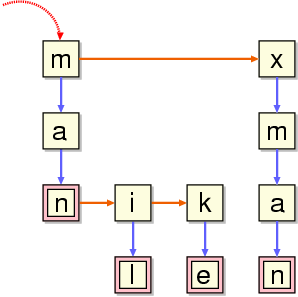
トライを簡略化した木
この簡略化したトライでは、メモリの消費を押さえるために、無駄 な枝と節をすべて省いている。探索はトライと同様に矢印で示した 根から開始する。トライではキーの文字に対応する枝を選ぶだけで 探索を進めることができたが、この木では
- キーの文字と節の文字を比較して
- 同じならば下の節へ進む
- 異なれば右の節へ進む
- 進む先の節がなければ探索終了
というアルゴリズムで探索を進める。従って、同じ段にたくさんの 文字の種類がある場合は、右の節へ進む回数が多くなり、トライほ どの性能は得られない。しかし、探索に要する時間は、最大でも文 字の種類×キーの長さで済むため、辞書に登録されている項目が増 えても高速に辞書検索が行える。
メッセージの表示
chatty は watch_input 関数でユーザの入力を監視して、入力に応 じたメッセージの表示を行う。辞書の検索はユーザが 1文字入力す るたびに行われる。たとえば、辞書に
xman うげ。こんなのあったのか
という項目が登録されている場合、ユーザが x m a n と各キーを入力するたびに辞書検索が行われ、最 後の n が打たれた瞬間にタイトルバーに「うげ。こんなの あったのか」というメッセージが表示される。
辞書検索の単純な方法としては、1打鍵ごとに 辞書の木に対して x → m → a → n と 1段づつ探索を進めていく方法がある。しかし、 この方法では w h i c h SPACE x m a nという入力に対し て、 木の探索が w から行われるため、探索はいきなり失敗に終わ り、メッセージは何も表示されない。この場合、最後の n を打った瞬間に "xman" に対応するメッセージ「うげ。こんなのあっ たのか」が表示されて欲しいところである。
w h i c h SPACE x m a n という入力に対して "xman" のメッセー ジを表示する方法として、入力の文字列を後ろから遡って辞書検索 を行うというものがある。しかし、 "n", "an", "man", "xman", ..., "which xman" をキーとして何度も検索を繰り返すのは効率が 悪い。
そこで、chatty では、後ろから遡る辞書検索を効率よく行うため に、キーを逆向きにして辞書に登録するという手法を採用した。つ まり、"xman" の場合は、辞書に
namx うげ。こんなのあったのか
と逆向きのキーで登録する。他の項目についても同様に登録する と、さきほどの辞書は次のような木として再構成される。

キーを逆向きにした木
このように辞書の木を作っておけば、後ろから遡って辞書検索を行 う際に、木を n → a → m → x と 1段づつ探索を進めていけばよ く、効率がいい。
後ろから遡る検索を行いやすくするために、chatty では入力され た文字列も逆向きにして記録している。次の図は、入力 x m a n を文字列バッファ revbuf に逆向きに記 録していく様子を示している。図中に矢印で示した top は文字列 の先頭を表すポインタである。
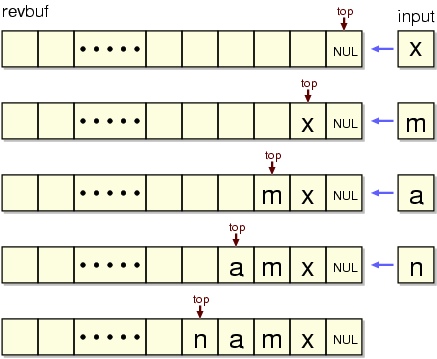
revbuf
入力の監視
入力の監視は、逆向きの文字列バッファ revbuf を用いて行われれ る。
void
watch_input (Dict *dict, RevBuf *revbuf, const char *str, int len)
{
int i;
for (i = 0; i < len; i++) {
int ch = str[i];
char *message;
if (revbuf_full_p(revbuf))
revbuf_clear(revbuf);
revbuf_add(revbuf, ch);
message = dict_search_longest(dict, revbuf_top(revbuf));
if (message)
printf("\033]0;%s\a", message);
if (ch == '\n' || ch == '\r')
revbuf_clear(revbuf);
}
}
watch_input 関数には標準入力から入力された長さ len の文字列 str が渡される。通常 watch_input 関数はユーザが 1文字入力す るたびに呼び出されるため、len の値はほとんどの場合 1である。
forループの中では、入力された文字を revbuf_add 関数で revbuf に追加し、dict_search_longest 関数で辞書検索を行っている。検 索が成功して message に値が入っているときは、端末の制御コードを 用いて printf 関数でメッセージをタイトルバーに表示する。
この端末の制御コードを用いれば、コマンドラインから次のように 実行してもタイトルバーへメッセージを表示することができる。
% printf '\033]0;%s\a' abc

printf
chatty ではタイトルバーにメッセージを表示する処理しか行えな いが、ユーザが入力した文字列に応じて計算機を喋らせたり、任意 のコマンドを実行できたりするとおもしろいかもしれない。
逆向きの文字列バッファ
逆向きの文字列バッファ revbuf は次の構造体で表現される。
typedef struct {
char str[BUFSIZ];
char *top;
char *tail;
} RevBuf;
revbuf の操作は
- revbuf_new -- バッファを新規作成
- revbuf_add -- バッファに1文字追加
- revbuf_top -- バッファの文字列の先頭を返す
- revbuf_clear -- バッファの内容をクリア
- revbuf_full_p -- バッファが一杯か調べる*7
という関数を用いて行う。これらの関数を用いてカプセル化を行う ことにより、構造体の内部構造を隠し、構造体を操作する際のミス を減らすことができる。また、操作に名前をつけることによって、 コードの意味を明白にし、プログラムの読みやすさを向上させる効 果も持つ。
カプセル化を行わないで構造体を直接操作することもできるが、そ の場合はコードが複雑になりやすい。私はそのような (抽象的の反 対の意味で) 具体的なコードのことを「生々しいコード」と呼んで いる。
辞書検索
辞書検索は dict_search_longest 関数によって行われる。1つめの 引数にメッセージの辞書を、2つめの引数に検索に用いるキーを渡 す。dict_search_longest は、指定したキーに最も長くマッチする 項目を検索し、メッセージを文字列のポインタとして返す。
watch_input 関数では、
message = dict_search_longest(dict, revbuf_top(revbuf));
のようにキーとして revbuf の先頭を渡して辞書検索を行っている。 従って、ユーザが "which xman" と入力した時点では、 "namx hcihw" がキーとして検索に用いられる。
辞書の木の探索は n → a → m → x のように進み、進む先の節が なくなった時点で終了する。この例では "namx" の項目が指定した キーに最も長くマッチするため、メッセージ「うげ。こんなのあっ たのか」が検索結果として返される。
辞書の実装
トライを簡略化した木を表現するデータ構造として、次のような構 造体を定義した。
typedef struct _DictNode {
int symbol; ← 文字 (例: 'x')
char *key; ← キー (例: "xman")
char *value; ← メッセージ (例: "うげ。こんなのあったのか")
struct _DictNode *child; ← 下方向の節へのポインタ
struct _DictNode *next; ← 右方向の節へのポインタ
} DictNode;
木は節 (node) の集まりとして表現できるため、節と節をポインタ で繋げていくだけで木を作ることができる。chatty では、この DictNode 型を操作する関数として、次のようなものを用意した。
- dictnode_new -- 節を新規作成
- dictnode_destroy -- 節を解放
- dictnode_define -- 節にキー (key) とメッセージ (value) を定義
- dictnode_empty_p -- 節の中身が空か調べる
- dictnode_find_node -- 指定した文字を含む節を同じ段から探す
- dictnode_add -- キーとメッセージを木に追加
- dictnode_get -- 木を指定したキーで探索し、見つかった節を返す
- dictnode_traverse -- 木の全探索を行い、各メッセージごとに何か処理を行う
これらの関数は GLib*8の流儀を 模倣して設計を行った。C言語でオブジェクト指向プログラミング を行う例として GLib のソースコードはためになる。chattyのソー スコード (dict.c) は、その簡単な例として参考になるかもしれな い。
C言語でビジターパターン
dictnode_traverse 関数は『デザインパターン』*9 でいうところのビジターパターンを C言語で実装した例である。ビ ジターパターンは、木構造のようなデータ構造に対して、探索を行 いながら各要素に処理を適用するときに用いるデザインパターンで ある。
dictnode_traverse 関数では、木の全探索を行い、メッセージを含 む節を見つける度に引数で指定されたコールバック関数の適用を行 う。
static void
dictnode_traverse (DictNode *node,
DictTraverseFunc traverse_func,
void *data)
{
if (node-> key && node->value)
traverse_func(node->key, node->value, data);
if (node->child)
dictnode_traverse(node->child, traverse_func, data);
if (node->next)
dictnode_traverse(node->next, traverse_func, data);
}
たとえば、木に登録されているキーとメッセージをすべて表示する には、
static void
print_entry (const char *key, const char *value, void *data)
{
printf("%s\t%s\n", key, value);
}
という表示用のコールバック関数を定義して、
dictnode_traverse(root, print_entry, NULL);
のように、dictnode_traverse 関数に、木の根 (root)とともに、 コールバック関数の関数ポインタ (print_entry) を渡せばいい。 この例では dictnode_traverse関数の第 3引数は利用していないが、 コールバック関数にデータを渡したいときはここに指定する。たと えば、
1 ekam ソースからビルドかよ 2 liam 仕事しないでメールばっかり 3 nam google使えよ 4 namx うげ。こんなのあったのか
のように、カウントしながら表示するには
static void
print_entry (const char *key, const char *value, void *data)
{
int *count = (int *)data;
(*count)++;
printf("%d %s\t%s\n", *count, key, value);
}
という表示用のコールバック関数を定義して、
int count = 0; dictnode_traverse(root, print_entry, &count);
のように、dictnode_traverse 関数を呼び出せばいい。コールバッ ク関数の中では void ポインタで渡されたデータ data を元の型の ポインタに戻す必要がある。ビジターパターンは Scheme や Ruby といったプログラミング言語ではクロージャという機構を用いて一 瞬でできる技法であるが、C言語では、このように面倒なコードを 書かなければならない。私は言語仕様の制限に起因するこのような 厄介なコードのことを「涙ぐましいコード」と呼んでいる。
辞書の内部実装の交換
前述の通り、chatty では辞書のデータ構造としてトライを簡略化 した木を採用した。しかし、将来的に必要に迫られ、あるいは気分 の問題として、別のデータ構造に変更したくなるかもしれない。
そこで、辞書検索の部分のコード (dict.[ch]) では、内部のデー タ構造を簡単に交換できるように、内部の実装とは独立して外向き の API を定義している。具体的には外向きの APIとして、Dict と いう型に対して次のような関数を用意した。
- dict_new -- 辞書を新規作成
- dict_destroy -- 辞書を解放
- dict_add -- キーとメッセージを辞書に追加
- dict_search_exact -- キーに完全に一致する項目を検索する
- dict_search_longest -- キーに最も長く一致する項目を検索する
- dict_traverse -- 辞書の各メッセージごとに何か処理を行う
Dict型の実体は、
struct _Dict {
DictNode *root;
};
という、単にメンバーに木の根を持つだけの構造体である。さきほ ど説明した dictnode_* という関数はすべて dict.c の中で、ファ イル内のローカルなスコープしか持たない static の関数として宣 言されている。従って、dict.c の外からは dictnode_* 関数を呼 び出すことはできず、必ず dict_* の関数を用いて辞書の操作を行 わなければならない。
このように内部の実装と外向きのAPI を分離しておくことにより、 内部のデータ構造を簡単に交換することができる。実際、私はリス トで辞書を実装したときにどの程度の性能が出るか調べるために、 内部構造を GLib のリストに交換した版の chatty を作って実験を 行った*10。また、chatty では行っていないが、内部の実装を分離しておけば、内部のデータ 構造を実行時に動的に交換するといった芸当も可能である。
テストの自動化
データ構造として木を扱うようなプログラムでは、きわどい条件分 岐や再帰的な関数呼び出しが行われるため、とかくバグが混入しや すい。従って、慎重にテストを行う必要がある。しかし、テストが 大切だとわかっていても、いちいち手でテストを行うのでは面倒に なってつい怠ってしまいがちである。そこで、chatty ではテスト の自動化を行った。テストを行うには、コマンドラインから make check と実行するだけでよく、ソースコードを変更するたびに頻繁 にテストを行っても苦にならない。
% make check make[1]: 入ります ディレクトリ `/home/satoru/work/chatty/tests' ./test-1 ./test-2 ok
テストの自動化を行うために、辞書に関するコードをテストするた めのプログラム dict-test を作成した。dic-test は
- 辞書に登録されているすべての項目を辞書の探索を行って出力する
- 辞書に登録されているすべてのキーに対して検索が正しく行えるかテストする
- 標準入力から指定されたキーを用いて辞書検索を行う
- 上の 3つの処理の性能を評価するためのベンチマークテストを行う
といった辞書のテストに必要な機能を持つ。たとえば、dict-test を用いれば、辞書に読み込まれた内容が、元の辞書と同じ内容を完 全に含んでいるか (1) の機能を用いて次のように簡単にテストで きる。
% ./dict-test -p chatty-dict.ja | sort > x # 1 % sort chatty-dict.ja > y # 2 % cmp x y && echo ok # 3 ok # 1. 読み込んだ辞書の内容をソートして x に出力 # 2. 元の辞書をソートして y に出力 # 3. x と y の内容が完全に同じか比較
tests ディレクトリに置かれたテスト用シェルスクリプト test-1, test-2 は、この dict-test を用いて各種のテストを行っている。 テストの自動化とその手法については『プログラミング作法』*11や『リファクタリング』に詳しい*12。
なお、chatty の場合は、小さなプログラムであるため用いなかっ たが、autotools*13 を用 いてソフトウェア開発を行う際には、automake が備えているテス ト自動化の枠組みを利用すると便利である。
メモリリークの検出
chatty では、動的にメモリを割り当てながら木の構築を行ってい る。このようにして作成した再帰的なデータ構造は、メモリリーク (メモリの解放し忘れ) を起こしやすい。
メモリリークを検出するツールとしては ccmalloc *14, MemProf *15, mpatrol *16, dmalloc *17 などさまざまなものがある が、私は ccmalloc が気に入って使っている。chatty では、辞書 のデータ構造の扱いにメモリリークがないか、ccmalloc つきの dict-test コマンドを用いてテストを行っている。
ccmalloc を利用するには
% gcc -g -o foo foo.c -lccmalloc -ldl
のように libccmalloc と libdl をリンクすればいい。 chatty の Makefile では make ccmalloc で ccmalloc つきでビルドが行える ように定義を行っている。
ccmalloc つきでコンパイルしたプログラムを実行すると、標準エ ラーに診断メッセージが出力される。メモリリークがないときの診 断メッセージは次のようなものである。
.---------------. |ccmalloc report| ======================================================= | total # of| allocated | deallocated | garbage | +-----------+-------------+-------------+-------------+ | bytes| 2951 | 2951 | 0 | +-----------+-------------+-------------+-------------+ |allocations| 141 | 141 | 0 | +-----------------------------------------------------+ | number of checks: 1 | | number of counts: 282 | | retrieving function names for addresses ... done. | | reading file info from gdb ... done. | | sorting by number of not reclaimed bytes ... done. | | number of call chains: 0 | | number of ignored call chains: 0 | | number of reported call chains: 0 | | number of internal call chains: 0 | | number of library call chains: 0 | `------------------------------------------------------
一方、メモリリークがあるときは、次のような診断メッセージが出 力される。
.---------------. |ccmalloc report| ======================================================= | total # of| allocated | deallocated | garbage | +-----------+-------------+-------------+-------------+ | bytes| 2951 | 364 | 2587 | +-----------+-------------+-------------+-------------+ |allocations| 141 | 1 | 140 | +-----------------------------------------------------+ | number of checks: 1 | | number of counts: 142 | | retrieving function names for addresses ... done. | | reading file info from gdb ... done. | | sorting by number of not reclaimed bytes ... done. | | number of call chains: 140 | | number of ignored call chains: 0 | | number of reported call chains: 140 | | number of internal call chains: 140 | | number of library call chains: 0 | ======================================================= | : | | 0.8% = 20 Bytes of garbage allocated in 1 allocation | | | | 0x40047306 in <???> | | | | 0x080495a5 in <main> | | at dict-test.c:197 | | | | 0x080499d5 in <dict_new> | | at dict.c:202 | | | | 0x0804960c in <dictnode_new> | | at dict.c:78 | | | `-----> 0x08049e32 in <malloc> | at src/wrapper.c:284 :
この診断メッセージには、どの malloc がメモリリークを引き起こ しているかが、関数呼び出しのスタックトレースつきで表示される ため、メモリリークの原因追求にたいへん役立つ。この例ではmain 関数から呼ばれた dict_new 関数から呼ばれた dictnode_new 関数 から呼ばれた malloc (dict.cの78行目) がメモリリークを引き起 こしていることがわかる。診断メッセージにファイル名と行番号が 表示されているのは、コンパイル時に gcc に渡した -g オプショ ンが効いているためである。
性能評価
chatty では、辞書の項目が増えても高速な検索が行えるデータ構 造としてトライを簡略化した二分木を採用した。わざわざこうした データ構造を実装したからには、本当に高速なのか確認したいとこ ろである。そこで、前述の dict-test のベンチマークテスト機能 を利用して、性能評価を行った。
小さな辞書では性能評価にならないため、ベンチマークテストには GENE95辞書 *18 を加工したものを用いた。これは 約 57,000項目を持つ 約2.5 MB の英和辞書である。Pentium 266 MHz + メモリ 64 MB のやや古い PCで、辞書を読み込みんで辞書に登録されているすべてキーを検索 する、というベンチマークテストを行ったところ、次の結果が得ら れた。
% ./dict-test -bc gene.dic == read_dict : 1.83 sec. == traverse(check): 0.31 sec.
この結果から、辞書の読み込みに 1.83秒、すべてのキーの探索 に0.31 秒かかっていることがわかる。
一方、辞書を GLib のリストで実装した辞書の場合は、辞書の読み 込みこそ 0.6 秒で完了するものの、すべてのキーの探索には 775.59秒もの時間を要した。リストでは、巨大な辞書に対して高速 な検索が行えないことがわかる。
% ./dict-test2 -bc gene.dic == read_dict : 0.60 sec. == traverse(check): 775.59 sec.
この他にも、別のデータ構造で辞書を実装して性能の比較を行い、 より高速な辞書検索を目指すとおもしろそうである。辞書に適した データ構造としては他に、ダブル配列*19、 パトリシア木*20、Suffix Array*21 などがある。
chattyの誕生
chatty のアイディアは Lispマニアの大和正武氏との雑談から生ま れた。大和氏は、以前に私が口走った「これからは、まったり系ソ フトの時代っすよ」という出任せの発言にヒントを得て、nagoyal という名の「なごみ系ソフト」を開発した。まったり系ソフトの開 発を試みたものの失敗してなごみ系ソフトになってしまったそうで ある。
nagoyal は configure スクリプト*22 が出力する診断メッセージに「なごみ系」の言葉をさりげなく挿入 する。configure が正常に通ることを祈りつつ緊張した面持ちでメッ セージを眺めていると、
checking for a BSD compatible install... /usr/bin/install -c checking whether build environment is sane... yes checking for K&R... 机がちらかりすぎててみつからん checking for working aclocal... found checking for your lunch... うな重
といった他愛もない言葉が現われてプログラマの心がなごむという 仕掛けである。大和氏が nagoyal が実際に動かしているのを見て、 私はくだらなさに唖然とした。
chattyのアイディアは、nagoyal を発展させてもっとくだらないも のを作ろう、と大和氏と雑談しているうちに生まれたものである。 このアイディアを友人の日台健一氏に話したところ、その日のうち に小うるさい端末のプロトタイプができ上がった。chatty は日台 氏のプロトタイプを参考にして私が実装し直したものである。
おわりに
今回は役に立たないソフトウェアの一例として chatty を取り上げ、 chatty の開発を例にとってプログラミングの技法をいくつか紹介 した。横着なことばかり追究していないで、たまにはこうしたくだ らないソフトウェアを真剣に作るのもいいんじゃないかと思ってい る。
参考文献
- Erich Gamma, Richard Helm, Ralph Johnson, John Vlissides 著, 本位田真一, 吉田 和樹 訳 『デザインパターン改訂版』 , 1999, ソフトバンク
- Brian W. Kernighan, Rob Pike著, 福崎 俊博 訳, 『プログラミング作法』 , 2000, アスキー
- Martin Fowler著, 児玉公信, 友野晶夫, 平澤章, 梅澤真史 訳, 『リファクタリング: プログラミングの体質改善テクニック』 , 2000, ピアソン